Can Sparse Autoencoders Be Used for OOD Detection?
Published on: Jun 4, 2025
While exploring Sparse Autoencoders (SAEs), one question that struck me was: Can SAEs provide a useful signal for out-of-distribution (OOD) detection?
What are Sparse Autoencoders?
Sparse Autoencoders are a class of autoencoders that introduce sparsity constraints on the hidden representations.
They are widely used in machine learning interpretability for transforming polysemantic features (those that entangle multiple concepts) into monosemantic features (more disentangled and interpretable features).
Typically, for an input of dimension f and hidden dimension d (where d > f), an unconstrained autoencoder could trivially learn the identity function.
To avoid this, an L1 regularization term is added to encourage sparsity in the hidden layer, forcing the network to activate only a small subset of neurons.
This principle is connected to sparse dictionary learning and has gained popularity in mechanistic interpretability.
What Is OOD Detection?
Out-of-Distribution (OOD) Detection is the task of flagging inputs that differ from the training distribution, often called in-distribution (ID).
The goal is to detect whether a test sample comes from a distribution that was not seen during training, which is crucial for safety-critical applications.
Given the disentangled structure that SAEs impose, a natural question arises: Can the sparse latent space learned by SAEs enhance ID/OOD separability?
Experiment Design
To explore this question, I performed a series of experiments using the following setup: A simple Multilayer Perceptron (MLP) with:
One hidden layer (h = 1024)
Input dimension (f = 512)
ReLU activation
L1 regularization for sparsity in the hidden layer
The SAE was trained using CIFAR-10 as ID dataset. For OOD analysis, I used two datasets:
MNIST (as a far-OOD case)
TinyImageNet (TIN20) (as a near-OOD case)
Visualization and Observations
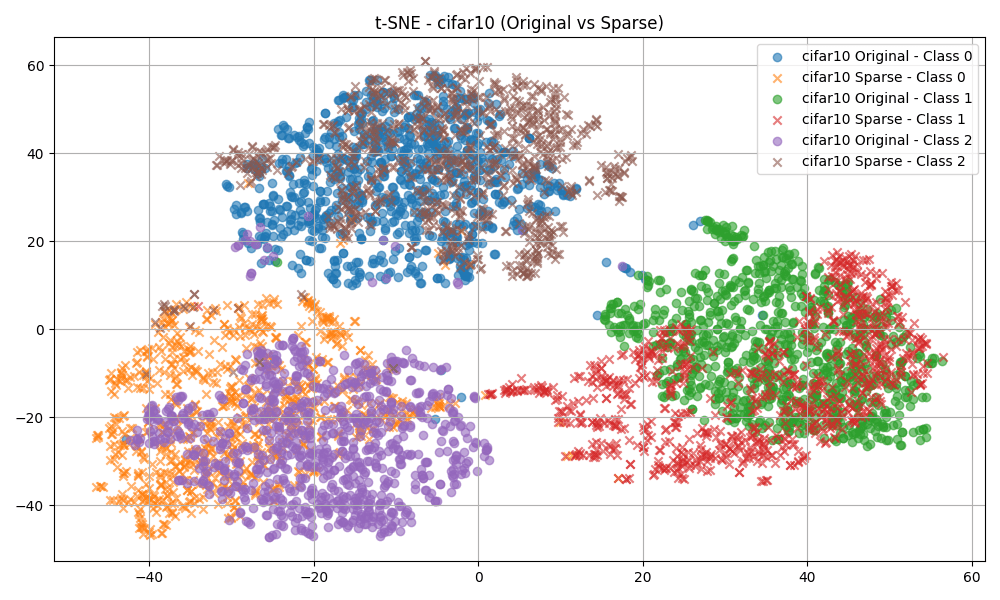
I visualized the hidden layer activations (both original and sparse) using t-SNE for ID dataset.
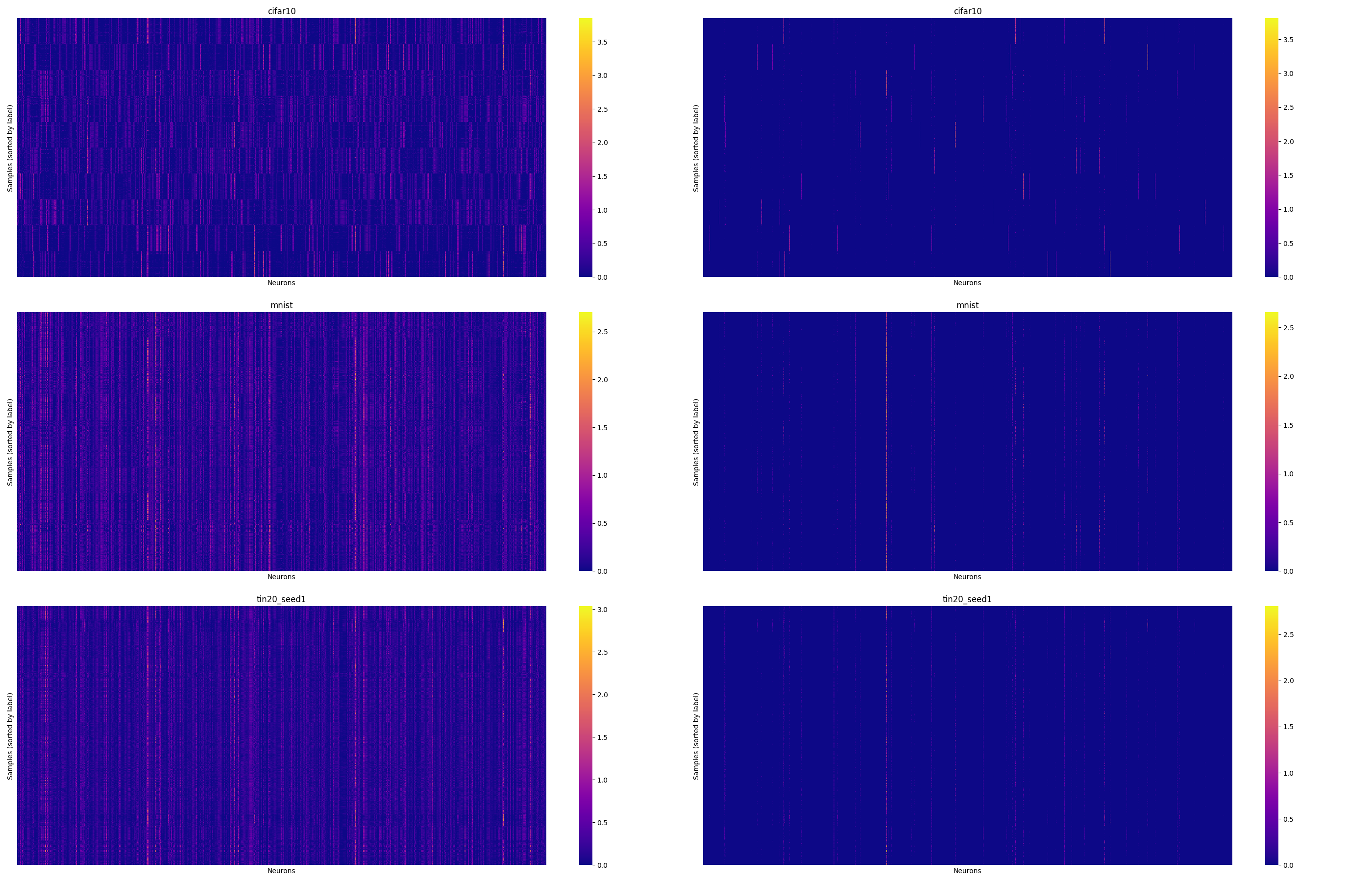
Fig 1: t-SNE plots for original and sparse activations for first 3 classesFig 2: Neuron activations for ID (CIFAR-10) and OOD (MNIST & TIN20) samples
Observations:
From Fig 1. it was hard to find to any insights.
In Fig 2. the sparse representation of CIFAR-10 (right of Fig 1), a few neurons per class showed high activation magnitudes.
For OOD samples, there were neurons that fired consistently across multiple samples, but some of these neurons also overlapped with those activated for ID samples.
While some separation was visible, the overlap complicated the interpretation.
These patterns were consistent across multiple datasets.
Next was to decide what method could help us extract this information.
I tested three strategies to exploit the sparse representations for OOD detection:
Reconstruction Error Per Class:
Rationale ID samples should reconstruct better than OOD samples.
Implementation Measure reconstruction error for each test sample. Higher errors would indicate potential OOD samples.
L2 Distance from Class Means:
Rationale The latent representations of ID samples should be closer to their class means in the sparse space.
Implementation For a given test sample, compute its L2 distance from each class mean. Smaller minimum distances are expected for ID samples.
Subspace Projection on Class-Specific Bases:
Rationale The decoder weights of the SAE can be seen as a learned basis that reconstructs activations from a sparse code.
Implementation Project test samples onto class-specific subspaces formed from decoder weights. Higher projection magnitudes may suggest ID alignment.
Final Thoughts
The final results were comparable to those obtained by applying L2 distance from class means directly on the original feature space.
This raises an important question:
Can sparse representations discovered by SAEs provide any additional or novel information for OOD detection beyond what is already available in the feature space?
Or more pointedly:
Is the OOD detection performance achieved in the original feature space an upper bound for what SAEs can offer in this context?
While SAEs help disentangle activations and impose sparsity, in this setup they did not provide a clear advantage for OOD detection.
It remains an open question whether better architectural choices, training regimes, or evaluation metrics might reveal deeper utility in the sparse representations.
Such performance results could have also been due to the inherent limitations of SAEs like reconstruction errors of the hidden representations might lead some information loss.
Similarly, Sparse Dictionary Learning assumes the Linear Representation Hypothesis in non linear models.
Nonetheless, the exploration helped refine my understanding of both interpretability tools and robustness evaluation.