Adversarial Machine Learning
I came across a Notion page of my undergraduate thesis. Although it's not structured properly, I found some interesting elements.
Adversarial Machine Learning is the field of study that focuses on attacks on machine learning algorithms and defenses against such attacks. These attacks are carried out by adding perturbations that manipulate the input-output mapping learned by the neural network. Perturbed inputs are indistinguishable from the original input. The presence of such adversarial examples is the inherent weakness of the neural network which causes it to work well on naturally occurring data but can drastically change a network's response when the points lie outside of the data distribution.
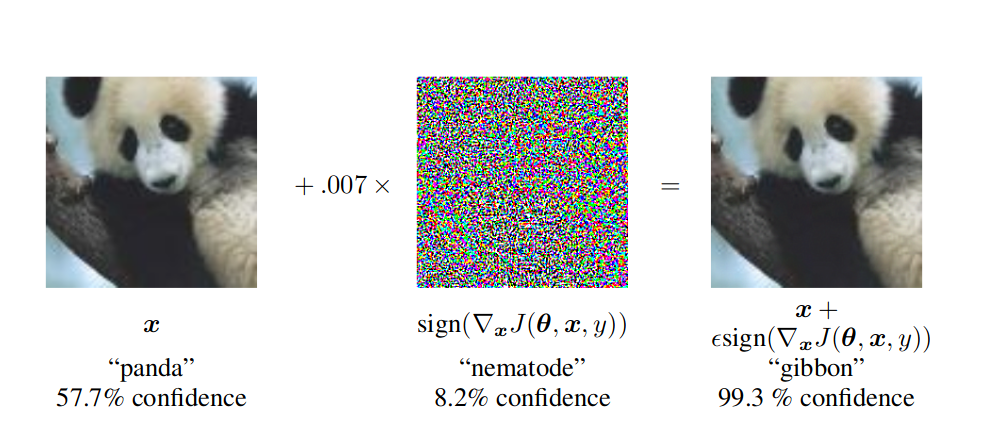
In an adversarial environment, it is anticipated that the adversarial opponent tries to cause machine learning to fail in many ways. An adversary can poison a model’s classifications, often in a highly targeted manner by crafting input data that has similar visual features to normal data but is capable of fooling the model as seen in fig 1.
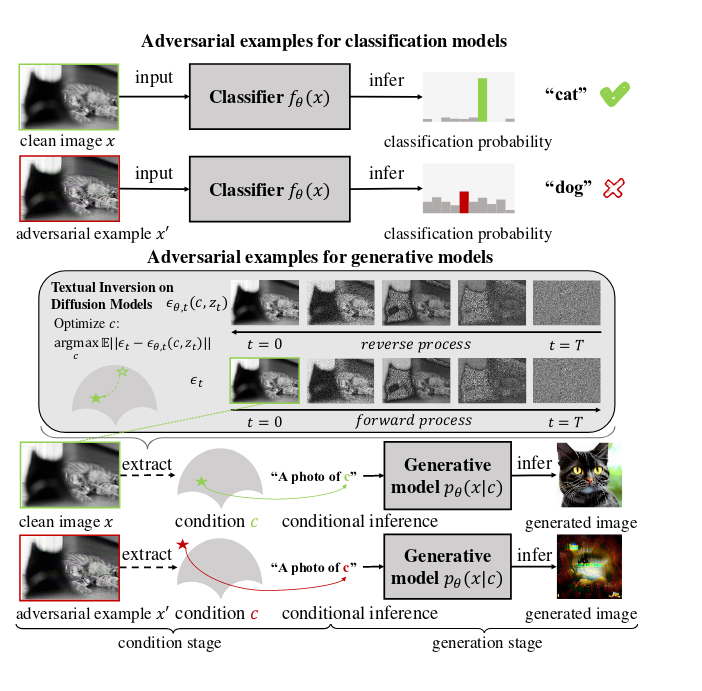
[2] shows an intersting visualization on how adversarial examples in diffusion models prevent diffusion models from extracting image features as conditions by inducing out-of-distribution features.
- Black box
- White box
- Single pixel attack
- Fast Gradient Sign Method (FGSM)
- Iterative-Fast Gradient Sign Method (IFGSM)
- Jacobia-Based Saliency Map Attack
- Carlini and Wager Attack
Answer from: [3]
Concept sparsity makes it feasible to poison text-to-image diffusion models
While the total volume of training data for diffusion models is substantial, the amount of training data associated with any single concept is limited, and significantly unbalanced across different concepts. For the vast majority of concepts, including common objects and styles that appear frequently in real-world prompts, each is associated with a very small fraction of the total training set, e.g., 0.1% for “dog” and 0.04% for “fantasy” (LAION-Aesthetic dataset). Furthermore, such sparsity remains at the semantic level, after we aggregate training samples associated with a concept and all its semantically related “neighbors” (e.g., “puppy” and “wolf” are both semantically related to “dog”).
References
[1] Explaining and Harnessing Adversarial Examples | here[2] Adversarial Example Does Good: Preventing Painting Imitation from Diffusion Models via Adversarial Examples | here
[3] Nightshade: Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models | here