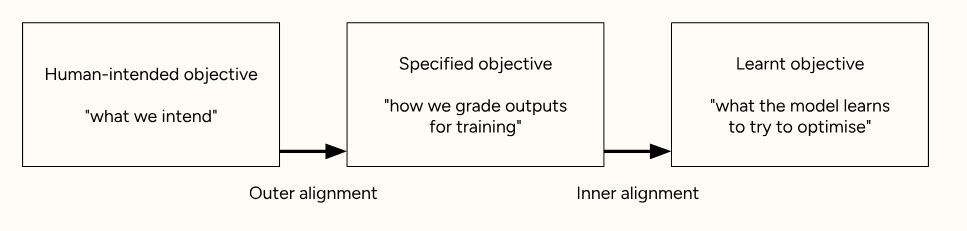
AI alignment: A subfield of AI safety which I like to view from the lens of robustness,
scalable oversight, and Mechanistic Interpretability. I try to avoid the use of alignment with human
values because different humans can have different values which can conflict sometimes.
Types of AI alignment:
Outer Alignment: If a system scores high against the reward function but behaves in a way that is not aligned with the true intentions of the creator.
Failure to define a reward funtion that truely/hollistically captures the human intetion/goal/objective could lead the system optimizing for targets that are only proxy of what we actually want.
Inner alignment: If a system fails to achieve the goals/objectives that it was designed for then its an inner alignment problem. This could occur due to problem in objective setting or optimization.
Fig 1: Types of AI alignment [1]Goodhart's law:
When a measure becomes a target, it ceases to be a good measure.
Any observed statistical regularity will tend to collapse when pressure is placed upon it for control purpose.
Qualia
It is subjective, individual experiences of perception and sensation.
For example, when you see a red apple, the redness you perceive is a quale. Even if we understand the neural processes and wavelengths
of light involved in seeing red, it doesn't fully explain the subjective experience of redness itself.
Four background claims (Machine Intelligent Research Institute (MIRI)) [2]
Humans have very general ability and can achieve goals across various domains. --> Intelligence/General Intelligence
AI systems could become much more intelligent than humans.
If we create highly intelligent AI systems, their decision will shape the future.
Highly intelligent system won't be beneficial by default.
To sum-up:
These four claims form the core of the argument that artificial intelligence is important: there is
such a thing as general reasoning ability; if we build general reasoners, they could be far smarter
than humans; if they are far smarter than humans, they could have an immense impact; and that impact
will not be beneficial by default.