So why do we need to initialize weights in deep learning?
Published on: May 22, 2024
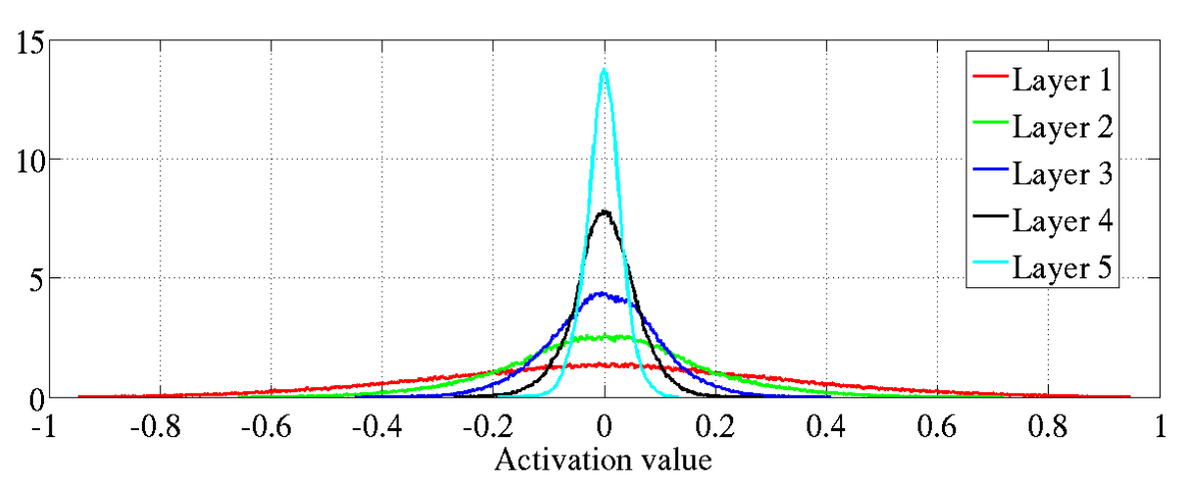
Here's a visualization of how mean activation and gradient values differ with and without initialization. These experiments were performed in the paper that introduced "Xavier initialization." The researchers used a 5-hidden-layer network for their analysis. Fig: 1. Activation values with standard initialization 2. Gradient values with standarad initialization : Source Xavier initilizationFig: 2. Activation values with xavier initialization 2. Gradient values with xavier initialization : Source Xavier initilization
Without initialization (standard initialization), activation and gradient values tend to vanish. This is evident in the gradient value histogram, where backpropagation leads to vanishing values as we move from layer 5 to layer 1. The figure above clearly demonstrates the need for initialization, as seen in the second picture. But why does initialization lead to such consistency? Let's explore this next.
yl = Wl * xl + bl
In the following equation, bold letters are used to represent vectors.
To define every term in the equation:
is the weight matrix of size from layer l-1 to l.
is the output of l-1 layer that was passed through activation function f(.). It is a vector.
represents biases of layer l.
is the output of the layer l before it is passed to an activation function.
Some assumptions have to be made to move further:
Elements of are independent to each other and share the same distribution.
Elements of are independent to each other and share the same distribution.
Both and are independent to each other.
If we take variance of this expression than we get a diagonal matrix, because of the independence of the variables. Variance of the right handside is eqal to the trace of the covariance of the left handside (need to see why).
Because the variables are independent to each other variance of sum is sum of variance,
Further, simplifying it we get,
Relation between variance and expectation is given by,
So,
If we choose the distribution of w_l such that its mean is zero, then we can write,
Note that we aren't making any assumptions about the mean of x_l so,
Two of the most popular initilization techniques are kaiming and xavier initialization. Xavier doesn't take activation into account while kaiming does. Let's move forward with kaiming initilization. Lets assume activation used in the previous layer is ReLU activation, which is given by,
How did we get that (1/2)? Here, we assume that has zero mean and symmetric distribution
around 0 and .
So, has zero mean and has a symmetric distribution around zero. So, probability of
>0 is 1/2.
We can establish a recursive realtion from the above equation which is given by
This equation explains everything. For very deep neural networks (large L), if the term in brackets is less than 1, the variance of the activations in the final layer tends to shrink dramatically. Conversely, if the term is greater than 1, the variance can explode. This highlights why the ideal value within the brackets is 1. It helps maintain a balanced flow of gradients throughout the network, preventing both vanishing and exploding gradients during training.
An intersting observation is that the variance of first layer does not make much of a difference.
References
How to initialize deep neural networks? Xavier and Kaiming initialization | Here