If I were to write an abstract on my last three months (May-July, 2024), one of the keywords would undoubtedly be MOOD. But hold on, it's not mood swings - I'm talking about Medical Out-of-Distribution (MOOD).
Out-of-Distribution (OOD): OOD refers to data points that deviate significantly from the statistical
properties of the sample distribution (under the assumption that sample data points are identically
distributed). For instance, the average height of a Nepalese woman is 4 feet 11.39 inches, so a European woman with an average height of 5 feet 6 inches would be considered an OOD data point in this distribution.
OOD and Machine Learning
In machine learning, OOD data refers to instances whose statistical
properties differ significantly from the data that the model encountered during training.
Why does this matter? Because most models operate under the closed-world assumption, meaning
they expect training and testing data to share the same distribution.
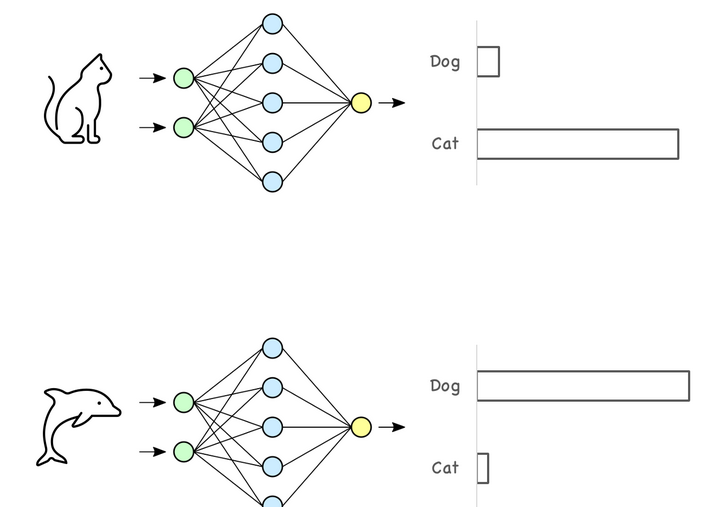
Imagine a neural network trained to classify cats and dogs. What happens if it encounters an image
of a fish in its testing dataset? The network will try to force the fish into one of the known
categories—cat or dog—likely with high confidence which is especially prevalent in networks trained with
cross-entropy loss function.
[1]
This scenario is common in real-world deployments, where the closed-world assumption often fails.
This issue becomes critical in domains like healthcare, where the consequences of a model making an
incorrect prediction with high confidence can be dire. The medical field is highly vulnerable to OOD
problems due to the difficulty in obtaining training datasets-and the resulting long tailed distribution
of classes.